序列化与反序列化
常见的序列化方式有:
JDK(不支持跨语言)、JSON、XML、Hessian、Kryo(不支持跨语言)、Thrift、Protostuff、FST(不支持跨语言)
技术选型关键点:
协议是否支持跨平台,序列化的速度(时间开销,系统性能),序列化出来的大小(空间开销,减轻网络、磁盘压力)。
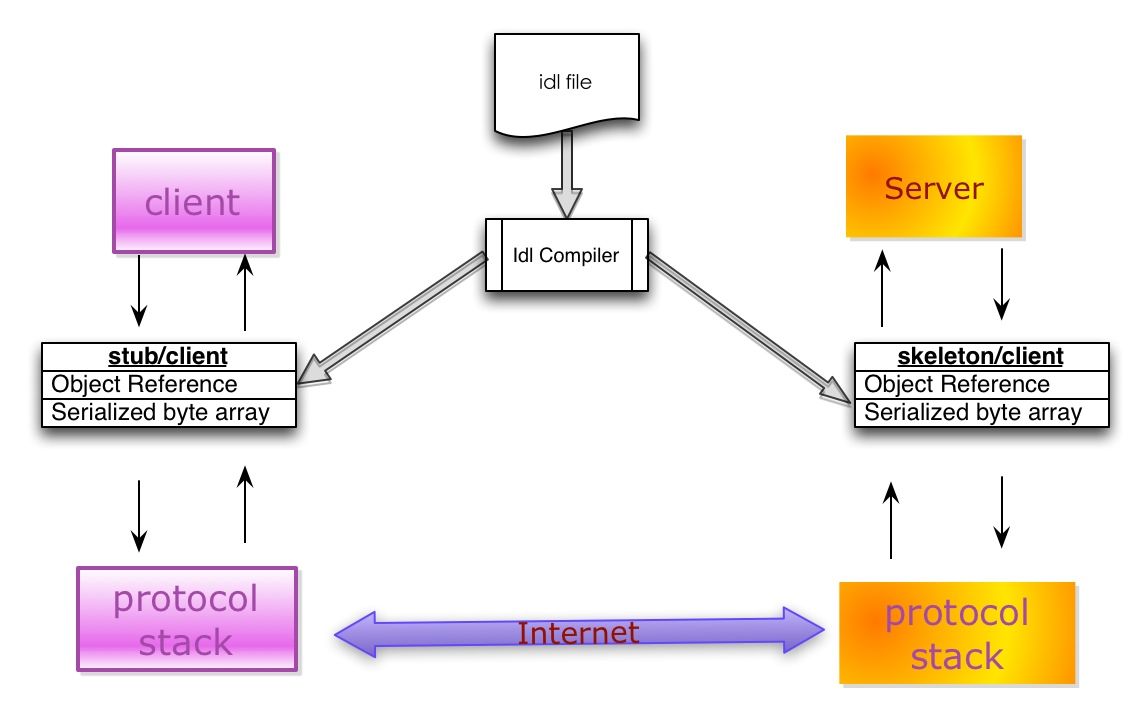
典型的序列化和反序列化过程往往需要如下组件:
- IDL(Interface description language)文件:参与通讯的各方需要对通讯的内容需要做相关的约定(Specifications)。为了建立一个与语言和平台无关的约定,这个约定需要采用与具体开发语言、平台无关的语言来进行描述。这种语言被称为接口描述语言(IDL),采用IDL撰写的协议约定称之为IDL文件。
- IDL Compiler:IDL文件中约定的内容为了在各语言和平台可见,需要有一个编译器,将IDL文件转换成各语言对应的动态库。
- Stub/Skeleton Lib:负责序列化和反序列化的工作代码。Stub是一段部署在分布式系统客户端的代码,一方面接收应用层的参数,并对其序列化后通过底层协议栈发送到服务端,另一方面接收服务端序列化后的结果数据,反序列化后交给客户端应用层;Skeleton部署在服务端,其功能与Stub相反,从传输层接收序列化参数,反序列化后交给服务端应用层,并将应用层的执行结果序列化后最终传送给客户端Stub。
- Client/Server:指的是应用层程序代码,他们面对的是IDL所生存的特定语言的class或struct。
- 底层协议栈和互联网:序列化之后的数据通过底层的传输层、网络层、链路层以及物理层协议转换成数字信号在互联网中传递。
序列化组件与数据库访问组件的对比
数据库访问对于很多工程师来说相对熟悉,所用到的组件也相对容易理解。下表类比了序列化过程中用到的部分组件和数据库访问组件的对应关系,以便于大家更好的把握序列化相关组件的概念。
| 序列化组件 | 数据库组件 | 说明 |
|---|---|---|
| IDL | DDL | 用于建表或者模型的语言 |
| DL file | DB Schema | 表创建文件或模型文件 |
| Stub/Skeleton lib | O/R mapping | 将class和Table或者数据模型进行映射 |
References:
https://tech.meituan.com/2015/02/26/serialization-vs-deserialization.html